EvilFlowers Text Service
1. Účel systému
Systém zabezpečuje plnohodnotný kanál od akademického PDF dokumentu až po sémantické vyhľadávanie nad uloženými vektorovými reprezentáciami textu. Cieľom je:
- bezstratovo extrahovať text (vrátane slovenskej diakritiky),
- konzistentne ho štruktúrovať (strany, odseky, vety),
- pripraviť embeddingy vhodné pre multijazyčné sémantické vyhľadávanie,
- ukladať ich do vektorovej databázy Milvus,
- sprístupniť vyhľadávanie cez API / mikroslužby (Django, Celery, Kafka),
- umožniť škálovanie na desiatky až stovky tisíc dokumentov.
2. High-level architektúra
End-to-end tok:
1. Vstup dokumentu
- Zdroj: lokálny súbor, upload cez API, správa z Kafka topicu (napr. „nový PDF dokument“).
- Dokument je uložený v súborovom systéme / objektovom storage (napr. S3/MinIO).
2. TextHandler / TextExtractor
- Na základe typu PDF:
- digitálne PDF → priama extrakcia textu cez PyMuPDF,
- naskenované PDF → OCR pipeline cez
ocrmypdf+pytesseract. Výstup: štruktúrovaný zoznam strán vo forme slovníkov:
{
'page_num': int,
'text': str,
'paragraphs': List[str],
'sentences': List[str]
} - Voliteľne aj TOC (obsah) v samostatnej štruktúre.
3. TextProcessor (chunkovanie pre embeddingy)
Post-processing extrahovaného textu:
- detekcia jazyka (slovenčina / angličtina),
- sémantické delenie na bloky vhodné pre embedding (napr. 512 tokenov, prekrytie 50 tokenov),
- príprava metadát (ID dokumentu, číslo strany, index odseku, dĺžka textu).
V aktuálnej implementácii je chunkovanie realizované priamo v SemanticIndexer._prepare_chunks() na úrovni strán/odsekov; neskôr sa rozšíri o LlamaIndex SentenceSplitter.
4. SemanticIndexer
Zodpovedný za:
- prípravu chunkov z dát TextHandleru/Processoru,
- generovanie embeddingov pomocou
EmbeddingGenerator, - uloženie embeddingov a metadát do Milvus cez
MilvusManager.
5. MilvusManager (vektorová databáza)
Správa kolekcie vo vektorovej DB Milvus / Milvus Lite:
- schéma,
- indexy (HNSW / AUTOINDEX),
- insert, search, delete, štatistiky.
6. SemanticSearch
- Generuje embedding pre dopyt (fulltextová veta alebo otázka),
- vykoná vektorovú query nad Milvus,
- vráti najrelevantnejšie úseky textu s metadátami (skóre, strana, typ chunka, náhľad textu).
7. Orchestrácia a integrácia
- Django REST API poskytuje HTTP endpointy:
- upload dokumentu a jeho indexovanie,
- sémantické vyhľadávanie,
- diagnostické endpointy (štatistiky kolekcie).
- Celery worker vykonáva ťažšie úlohy (extrakcia textu, embeddingy, indexovanie).
- Kafka topic slúži na integráciu s externými systémami (napr. Dataverse, iné repozitáre); správa obsahuje metadá o dokumente a cestu k PDF.
8. Testovanie a validácia
Špeciálny integračný test test_milvus_local.py:
- spúšťa pipeline nad reálnym PDF alebo nad vzorkou dát,
- používa Milvus Lite (embedded DB),
- overuje extrakciu, indexovanie, vyhľadávanie aj štatistiky kolekcie.
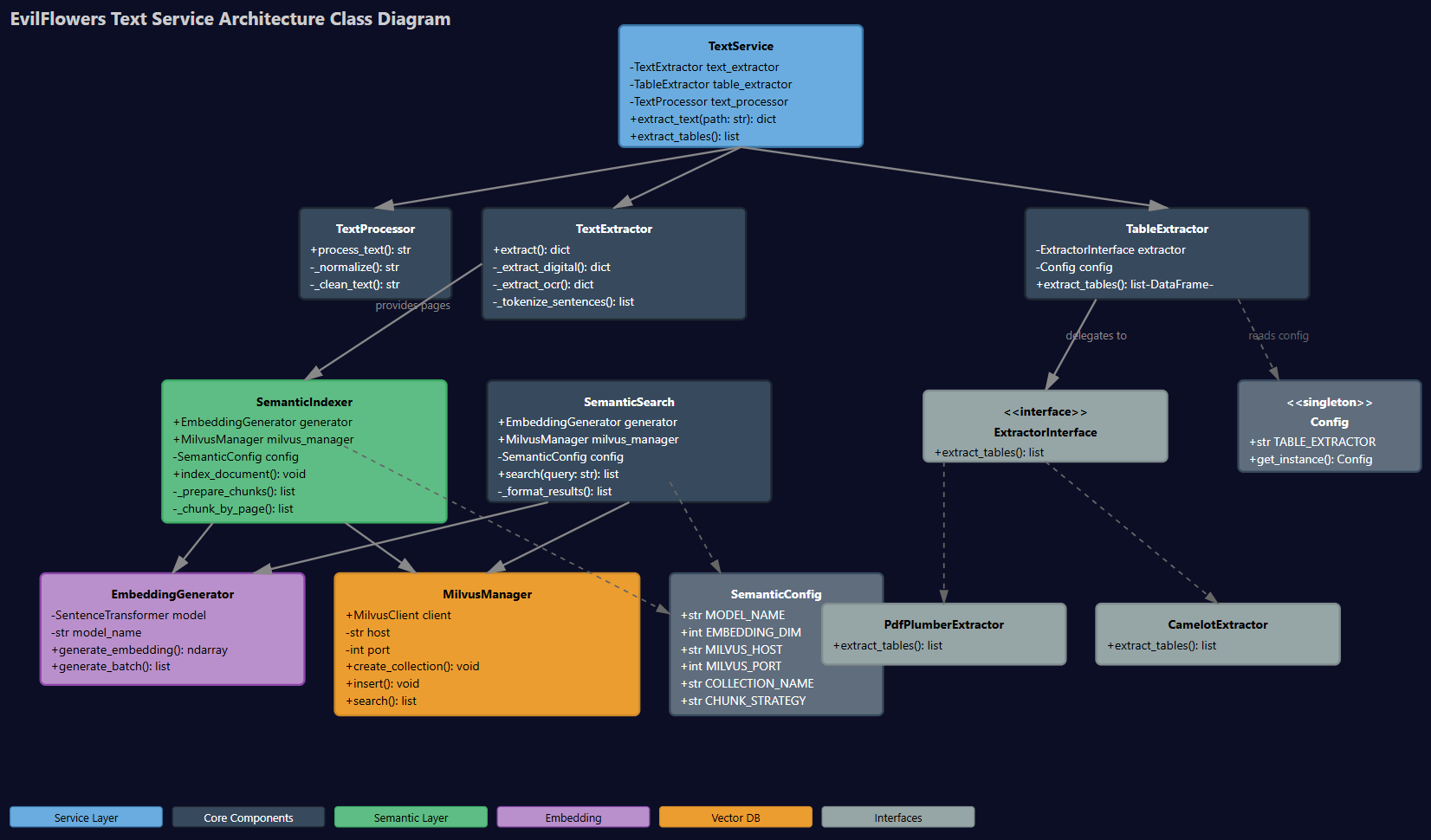
3. Komponenty
3.1 TextExtractor
Zodpovedá za všetku logiku okolo PDF:
- Validácia cesty k dokumentu.
- Otvorenie dokumentu cez
fitz.open. - Metóda
_is_digital(doc)rozhoduje medzi digitálnym a OCR režimom:- prechádza prvých N strán (max. 30),
- ak nájde dostatočne dlhý extrahovateľný text, dokument sa považuje za digitálny.
- Metóda
extract()je jediný vstupný bod:- pri digitálnom dokumente volá
_extract_digital(doc), - pri naskenovanom dokumente volá
_extract_ocr().
- pri digitálnom dokumente volá
Digitálna vetva (_extract_digital)
-
Používa
page.get_text("blocks")pre získanie blokov textu s pozíciou. -
Každý blok prechádza funkciou
_clean_whitespace:- opravuje hyfenizované word-\nwrap,
- nahrádza nové riadky medzerami,
- zjednocuje viacnásobné medzery.
-
Z blokov sa vytvára:
page_text– text celej strany,page_paragraphs– bloky dlhšie ako definovaný prah,page_sentences– rozdelenie na vety ceznltk.sent_tokenize.
Výsledok pre každú stranu:
{
'page_num': page_num,
'text': page_text,
'paragraphs': page_paragraphs,
'sentences': page_sentences
}
OCR vetva (_extract_ocr)
- Dokument sa spracuje cez
ocrmypdf.ocrdo bufferuBytesIO. - Následne sa PDF-byty konvertujú na bitmapové strany (
pdf2image.convert_from_bytes). - Z každej strany sa pomocou
pytesseract.image_to_stringvytiahne text. _split_into_paragraphsrozdelí text na odseky s heuristikami pre:- hlavičky (ABSTRACT, INTRODUCTION, atď.),
- kontaktné riadky (department, university, email),
- pokračovanie viet.
- Vety sa pri OCR vetve skladajú jednoduchším delením na „.“ s čistením.
TOC (obsah)
_check_tocobsahuje základnú heuristiku na detekciu prítomnosti obsahu._extract_tocje zatiaľ stub – bude doplnený podľa potreby:- extrakcia štruktúrovanej hierarchie kapitola → podkapitola → strana,
- použitie pre navigáciu pri vyhľadávaní / zobrazení výsledkov.
3.2 TextHandler / TextService
TextHandlerzapúzdruje prácu sTextExtractora prípadné ďalšie kroky (napr. detekcia TOC).- Typický tok:
- inicializácia
TextHandler(pdf_path), - volanie
extract_text(found_toc=False), - návrat
pages, toc.
- inicializácia
TextServicemôže poskytovať vyššiu vrstvu:- koordinácia ukladania surových strán do DB,
- volanie
SemanticIndexer, - logovanie a audit (čas spracovania, počty strán, jazyky).
3.3 SemanticIndexer
Zodpovedný za transláciu text → embedding → Milvus.
- Pri inicializácii vytvára:
EmbeddingGenerator(model),MilvusManager(kolekcia).
- Metóda
index_document(document_id, pages):- Zavolá
_prepare_chunks(pages):- podľa
SemanticConfig.CHUNK_LEVEL(paragraph / page), - pri odsekoch filtruje
_is_valid_paragraph(minimálny počet slov, filtrácia boilerplate typu Table of Contents, Zoznam obrázkov).
- podľa
- Pre vzniknuté
chunks: List[str]vygeneruje embeddingy:EmbeddingGenerator.generate_embeddings(...).
- Zavolá
MilvusManager.insert_embeddings(...)s embeddingmi a metadátami:page_num,chunk_type(paragraph / page),- index odseku,
- text (truncovaný na 2000 znakov),
- dĺžka textu.
- Zavolá
- Návratová hodnota obsahuje:
success,chunks_indexed,chunk_level,embedding_dim,document_id.
3.4 EmbeddingGenerator
Generuje vektorové reprezentácie textu pomocou sentence-transformers.
- Model sa načítava na základe
SemanticConfig.MODEL_NAME:- napr. BGE model (
BAAI/bge-m3) alebo XLM-R sentence-transformers.
- napr. BGE model (
- Používa konfigurované parametre:
SemanticConfig.DEVICE(„cpu“ / „cuda“),SemanticConfig.BATCH_SIZE,SemanticConfig.MAX_SEQUENCE_LENGTH.
- Metódy:
generate_embeddings(texts: List[str], ...) -> np.ndarray– batchové spracovanie,generate_single_embedding(text: str)– zabalené volanie pre jeden dopyt,get_model_info()– diagnostika konfigurácie modelu.
Embeddingy sú typicky normalizované (normalize_embeddings=True), čo je vhodné pre COSINE metriku v Milvus.
3.5 MilvusManager
Abstrakcia nad vektorovou DB Milvus:
- Podporuje dva režimy:
- Milvus Lite (embedded) – aktivovaný cez
USE_MILVUS_LITE=true,- pripojenie cez
connections.connect(alias="default",uri=db_file), - vhodné pre lokálny vývoj a integračné testy.
- pripojenie cez
- Milvus server – pripojenie na klasický Milvus cluster,
- host/port sa číta z
SemanticConfig.MILVUS_HOST,MILVUS_PORT.
- host/port sa číta z
- Milvus Lite (embedded) – aktivovaný cez
Schéma kolekcie
id– INT64, primárny kľúč, auto_id,document_id– VARCHAR(255),page_num– INT64,chunk_type– VARCHAR(50),paragraph_idx– INT64,text– VARCHAR(2000),text_length– INT64,embedding– FLOAT_VECTOR(dim =SemanticConfig.EMBEDDING_DIM),created_at– VARCHAR(50) (ISO timestamp).
Indexovanie
- Milvus Lite:
index_type = AUTOINDEX,metric_type = COSINE.
- Milvus server:
index_type = HNSW,- parametre napr.
M=16,efConstruction=256.
API metódy
insert_embeddings(document_id, embeddings, metadata) -> List[int]- vloží embeddingy a metadá, flushne kolekciu.
search(query_embedding, top_k, document_id=None, page_num=None) -> List[Dict]- podporuje filter cez
expr:- podľa
document_id, - podľa
page_num, - alebo kombináciu.
- podľa
- vracia zoznam výsledkov s:
id,score,distance,document_id,page_num,chunk_type,paragraph_idx,text,text_length.
- podporuje filter cez
delete_by_document_id(document_id) -> int- hromadné zmazanie všetkých vektorov daného dokumentu.
get_stats()- názov kolekcie, počet entít, embedding_dim.
close()- uvoľnenie kolekcie a odpojenie.
3.6 SemanticSearch
Komponent na strane vyhľadávania (kód nie je uvedený, ale logika je daná použitím v testoch):
Pri inicializácii:
- vytvára
EmbeddingGenerator, - vytvára
MilvusManageralebo používa existujúcu instanciu (singleton).
Metóda search(query, top_k, document_id=None):
- vygeneruje embedding dopytu cez
EmbeddingGenerator.generate_single_embedding, - zavolá
MilvusManager.search(...), - výsledky transformuje na slovníky:
score,page_num,chunk_type,text, prípadne ďalšie polia.
Použitie:
- priamo v integračnom teste,
- v API endpointoch (napr.
GET /search?query=...&document_id=...).
4. Konfigurácia a prostredia
Konfigurácia je rozdelená na:
-
Environment variables (typicky nastavené v testoch / docker-compose):
USE_MILVUS_LITE– prepínač embedded vs. server,SEMANTIC_SEARCH_ENABLED– zapínanie/vypínanie sémantického vyhľadávania,EMBEDDING_DEVICE–cpu/cuda,EMBEDDING_BATCH_SIZE– veľkosť batchu pri generovaní embeddingov,CHUNK_LEVEL–paragraph/page,MILVUS_COLLECTION_NAME– názov kolekcie,MILVUS_LITE_DB– cesta k embedded DB súboru.
-
SemanticConfigobsahuje default hodnoty:MODEL_NAME,EMBEDDING_DIM,MAX_SEQUENCE_LENGTH,MIN_PARAGRAPH_LENGTH,MILVUS_HOST,MILVUS_PORT,- predvolený
CHUNK_LEVEL,BATCH_SIZE,DEVICE.
Environment variables majú prednosť pred hodnotami v SemanticConfig, čo umožňuje meniť správanie bez zásahov do kódu.
5. Identifikované a vyriešené kritické problémy
- Nesprávne použitie OCR v digitálnych PDF súboroch
- Pôvodne sa OCR používalo aj na digitálnych PDF → drastické spomalenie + straty v diakritike.
- Teraz
_is_digital()rozlišuje typ dokumentu aextract()smeruje buď na_extract_digital()(PyMuPDF) alebo_extract_ocr().
- Nekonzistencie vo formáte dátového kanála
- Pôvodný formát n-tíc bol nekompatibilný s novým
TextExtractorom. - Všetky následné komponenty (
TextProcessor,SemanticIndexer) pracujú so slovníkmi ({'page_num', 'text', 'paragraphs','sentences'}), čo je kompatibilné s JSON a znižuje krehkosť prenosu.
- Naivné spracovanie textu
- Jednoduché heuristiky lámali vety pri skratkách („prof.“, „napr.“) a nevedeli správne zlepiť hyfenizované slová.
- Zavedená funkcia
_clean_whitespacea použitienltk.sent_tokenizes podporou slovenčiny (punkt_tab). Čistenie sa vykonáva v jednom
Architecture Class Diagram