Image microservice
Image microservice je mikroslužba zodpovedná za extrakciu obrázkov z PDF dokumentov a ich následné spracovanie. Spracovanie obrázkov zahŕňa dve hlavné funkcionality:
- Image captioning - automatické generovanie stručných popisov obrázkov
- Image labeling - automatické generovanie označení/štítkov obrázkov predstavujúce kľúčové slová alebo kategórie spojené s obsahom obrázku
Image captioning a image labeling môžu slúžiť na lepšie pochopenie obsahu dokumentov a sú užitočné pre budúcu indexáciu obrázkov pomocou Elasticsearch-u, čo umožní efektívne vyhľadávanie a organizáciu obrázkov na základe ich obsahu. Z pohľadu používateľa je táto mikroslužba dôležitá, pretože prispieva k zjednodušeniu práci s obrazovými dátami, umožňuje rýchlejšie vyhľadávanie relevantných informácií a zvyšuje celkovú produktivitu pri práci s dokumentami.
Jednotlivé funkcionality (extrakciu, captioning, labeling) sme testovali na vedeckých dokumentoch s cieľom prispôsobiť riešenie špecifikám danej domény.
Extrahovanie obrázkov
Pre účely extrakcie obrázkov z PDF dokumentov sme vyskúšali viaceré voľne dostupné Python knižnice a identifikovali sme ich výhody a nevýhody:
- PyMuPDF - extrahuje obrázky v rôznych formátoch (.jpg, .png - s alfa kanálom) a dosahoval relatívne uspokojivé výsledky, ale nebol schopný správne extrahovať niektoré obrázky zobrazujúce diagramy (diagramy boli rozdelené na viacero samostatných obrázkov, ktoré neboli správne extrahované, čo viedlo k výskytu plne čiernych/bielych obrázkov)
- pdfplumber - relatívne dobré výsledky, ale tiež nebol schopný správne extrahovať niektoré obrázky zobrazujúce diagramy (diagramy boli takisto rozdelené na viacero samostatných obrázkov, ktoré však boli extrahované správne)
- PyPDF2 - neuspokojivé výsledky, neextrahuje všetky obrázky prítomné v dokumente
Spoločným problémom pri všetkých nástrojoch je, že extrahujú aj obrázky irelevantné pre naše potreby (napr. logá, fotografie autorov, atď.), čo si vyžaduje ďalšie spracovanie, napr. filtrovaním.
Architektúra mikroslužby je navrhnutá tak, aby umožňovala použitie viacerých Python knižníc na extrakciu obrázkov, ktoré bude možné nastaviť pomocou environmentálnej premennej (PyMuPDF alebo pdfplumber, prípadne aj ďalšie v budúcnosti).
Image captioning
V rámci captioning-u sme otestovali niekoľko modelov z platformy Hugging Face, pričom ako výsledný model sme zvolili robustný model PaliGemma (podpora 34 jazykov), ktorý dosahoval najlepšie výsledky a rozhodli sme sa ho implementovať do nášho riešenia. Aj v tomto prípade umožňuje architektúra mikroslužby integráciu aj ďalších modelov a modely voliť pomocou environmentálnej premennej.
Image labeling
Pre účely labeling-u sme taktiež pracovali s viacerými modelmi z platformy Hugging Face. Avšak, narazili sme na problém, že tieto modely boli trénované na obmedzenom počte tried a v odlišných doménach, čo ich robí nevhodnými na spracovanie vedeckých dokumentov obsahujúcich špecifické obrázky, ako sú zložité diagramy či grafy. I napriek týmto obmedzeniam sme sa rozhodli ponechať možnosť využitia AI modelov na generovanie štítkov, pretože môžu byť v budúcnosti užitočné pre dokumenty dostupné v knižnici ELVIRA. V rámci mikroslužby sme implementovali 2 modely, a to Vision Transformer a ResNet-50.
Keďže výsledky labeling-u pomocou AI modelov neboli uspokojivé, rozhodli sme sa implementovať aj prístup založený na image captioning-u, ktorý dokázal generovať najrelevantnejšie popisy obsahu obrázkov. Na extrakciu štítkov z týchto popisov sme použili Natural Language Processing (NLP) knižnicu spaCy (konkrétne model en_core_web_sm) na generovanie štítkov z vygenerovaného popisu, pričom sme identifikovali a vybrali kľúčové slová reprezentujúce štítky.
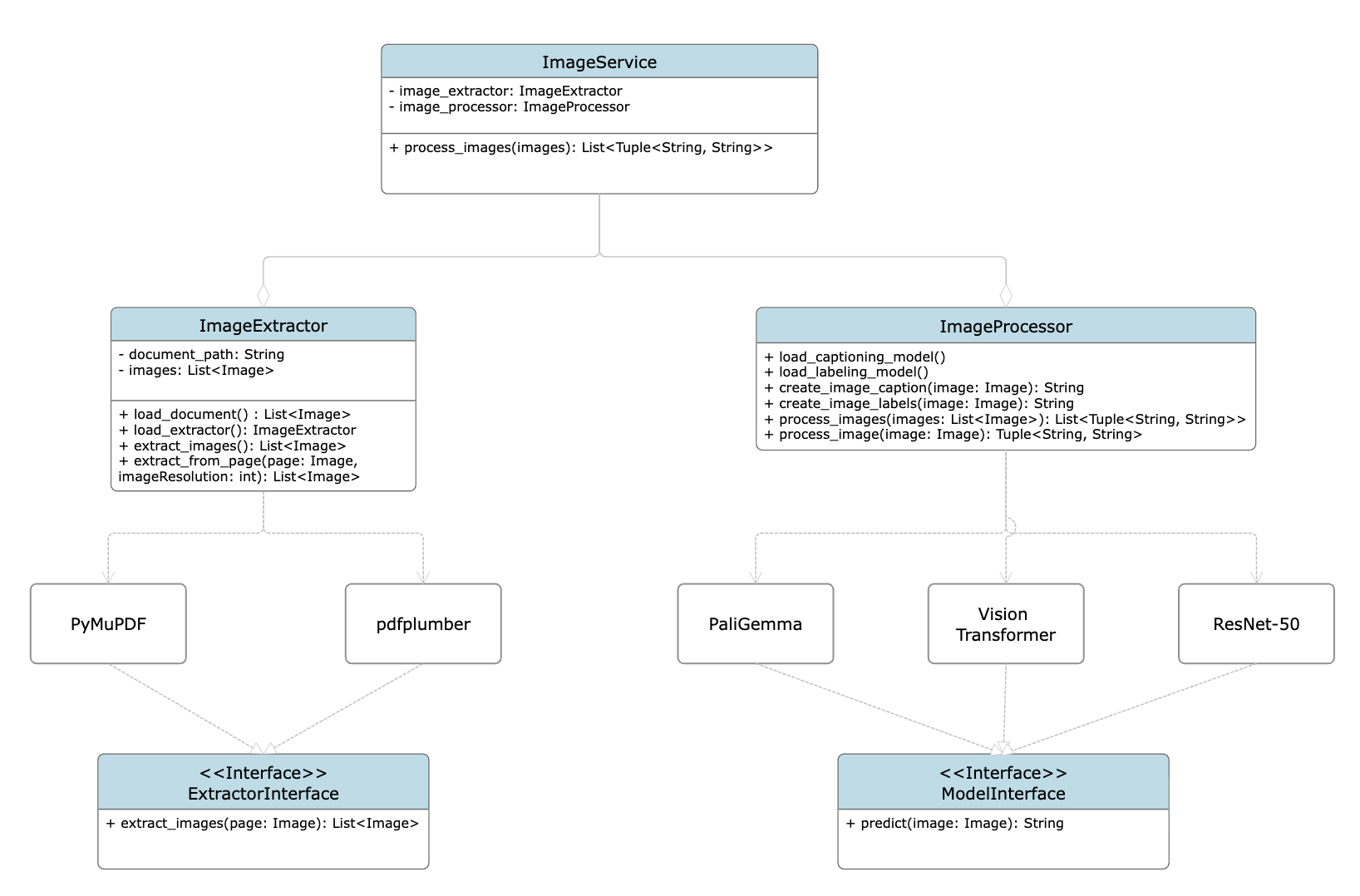
UML diagram
Základná podoba UML diagramu so vzťahmi medzi hlavnými prvkami mikroslužby je zobrazená na obrázku nižšie.